Введение
Многопоточный подход к
разработке приложений появился в программировании уже достаточно давно и широко
используется для повышения производительности. С появлением многоядерных
процессоров интерес к многопоточному программированию значительно усилился.
Многоядерные системы прошли путь от лабораторных образцов до настольных
компьютеров, доступных рядовым пользователям. В 2005 году началась массовая
продажа процессоров с двумя ядрами, в 2007 – четырехъядерных процессоров. В
будущем ожидается сохранение тенденции увеличения числа ядер, и можно с
уверенностью сказать, что с течением времени число систем, построенных на базе
многоядерных процессоров, будет постоянно увеличиваться.
В подобной ситуации
остро встает вопрос об эффективном использовании многоядерных архитектур.
Многопоточное программирование представляет собой очень удобный подход,
позволяющий создавать приложения, способные рационально использовать процессоры
с несколькими ядрами, обеспечивая их оптимальную загрузку. Уже сегодня
подавляющее большинство существующих приложений использует несколько потоков:
браузеры, файловые менеджеры, словари, антивирусы и многие другие. Можно
ожидать, что в дальнейшем все больше приложений будет изначально разрабатываться
как многопоточные.
Необходимо, тем не
менее, отметить, что разработка многопоточных приложений зачастую на порядок
сложнее, чем последовательных. Новая парадигма приносит не только новые
возможности, но и новые сложности. Создание эффективных многопоточных приложений
– весьма трудоемкий процесс, а значит, имеется насущная необходимость в
инструментальной поддержке всех стадий разработки подобных приложений, начиная с
построения архитектуры и заканчивая настройкой параметров и финальной
оптимизацией приложения.
В настоящее время
существует достаточно много инструментов, ориентированных на поддержку
многопоточного программирования. Компания Intel® выделяется на общем фоне тем, что
предлагает целое семейство подобных инструментов, представителем которого
является Intel® Thread
Profiler (ITP).
Семейство инструментов Intel® для поддержки разработки
многопоточных приложений
Цикл разработки
программных приложений включает в себя следующие основные стадии: анализ
требований, разработка архитектуры, реализация, тестирование, отладка и
оптимизация. Зачастую при этом приходится проходить несколько раз по каждой из
стадий. Эта деятельность разработчиков требует наличия специализированных
инструментов, и в настоящее время компания Intel® предлагает целый ряд программных
продуктов, предназначенных для поддержки разработки многопоточных
приложений:
-
Intel® C/C++ Compiler и Intel® Fortran Compiler –
компиляторы;
-
Intel® Performance Libraries – библиотеки
математических функций (численные методы, обработка сигналов, генераторы
случайных чисел);
-
Intel® VTune Performance Analyzer – профилировщик;
-
Intel® Thread Checker – отладчик многопоточных
приложений;
-
Intel® Thread Profiler – профилировщик многопоточных
приложений;
-
Intel® Threading Building Blocks – С++ библиотека
времени выполнения, представляющая набор примитивов для разработки
многопоточных приложений (параллельные алгоритмы, потокобезопасные структуры
данных, примитивы синхронизации).
Данное семейство
инструментов предназначено для поддержки всего цикла разработки многопоточных
приложений. Их конечная цель – значительно ускорить процесс разработки,
обеспечив разработчиков удобными и эффективными инструментами. Инструменты
поддерживают различные методы создания многопоточных приложений: OpenMP, Pthreads, Win32 threading API, автоматическое
распараллеливание. Более подробную информацию можно найти на сайте http://www.intel.com/software/products.
На рис. 1 схематически
представлен цикл разработки многопоточного приложения с указанием программных
продуктов Intel®,
предназначенных для помощи на соответствующих стадиях.
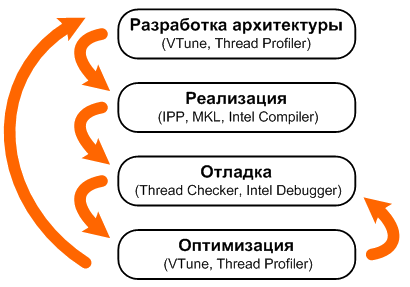
Рис. 1.
Цикл разработки приложения
Как видно из диаграммы,
ITP
в основном призван помочь разработчикам на финальных стадиях создания
многопоточного приложения. Он предназначен для профилирования многопоточных
приложений с целью их последующей оптимизации и финальной настройки. Однако
следует заметить, что ITP может оказаться полезным еще на стадии разработки
архитектуры. Разработчик имеет возможность сравнивать между собой различные
архитектурные решения, создавая прототипы и сравнивая их производительность при
помощи ITP и VTune.
Определение и цели профилирования
Центральная идея
ускорения последовательных приложений достаточно проста. Необходимо выявить
участки кода, в которых приложение проводит основную часть времени и
оптимизировать их. Известен эвристический закон «20/80», утверждающий, что
приложение проводит 80% времени работы в 20% кода. Таким образом, за счет
оптимизации именно этих 20% кода можно добиться значительного повышения
производительности. Как раз для поиска таких узких мест используются специальные
средства, называемые профилировщиками.
Под понятием профилирование
обычно понимается процесс анализа производительности приложения и учета
потребляемых им ресурсов. Тем самым, профилировщик – это инструмент, при помощи которого
осуществляется профилирование.
Профилировщики исследуют
поведение программы в процессе ее выполнения. В частности, собирается такая
информация, как частота вызовов функций, продолжительность их работы, число
потоков, время ожидания – любая информация, способная помочь при оптимизации
производительности. Для сбора информации профилировщики используют такие техники
как инструментация кода, аппаратные прерывания, внедрение счетчиков
производительности и многие другие. Выходной информацией профилировщика является
трасса – список событий, произошедших в
приложении (исполненные инструкции, вызовы функций, вызовы операционной
системы). После получения трассы профилировщик обрабатывает собранную информацию и строит профиль приложения – статистическую сводку о работе
приложения. Затем профиль представляется в графическом виде, удобном для
анализа. Разработчик изучает его, определяет проблемные места и ищет способы
оптимизации своего приложения.
Ситуация с
многопоточными приложениями существенно другая, поскольку в силу вступают новые
аспекты производительности, связанные с взаимодействием потоков, затратами на их
создание и синхронизацию. Ускорение отдельных участков кода может не дать
никакого прироста производительности, если, например, разработчик построил свое
приложение таким образом, что основную часть времени потоки ожидают освобождения
разделяемого ресурса. Также можно упомянуть такие распространенные в
многопоточных приложениях проблемы как неравномерное распределение нагрузки и
неэффективное использование примитивов синхронизации. Эти факторы могут привести
к катастрофически низкой производительности приложения, вплоть до того, что
многопоточная версия будет медленнее последовательной.
Таким образом, для
анализа новых аспектов программной оптимизации, присущих именно многопоточным
приложениям, необходимы специальные инструменты, ориентированные на обнаружение
проблемных ситуаций и последующей помощи программистам в их разрешении. Одним из
самых эффективных и популярных представителей инструментов такого класса
является ITP.
Назначение
Intel® Thread Profiler
ITP предназначен
для профилирования многопоточных приложений и помощи разработчику в процессе
оптимизации программного кода. Следует напомнить, что ITP также может быть
использован на стадии разработки архитектуры приложения. Разработчики могут
создать несколько прототипов, соответствующих различным архитектурным решениям,
и сравнить их производительность при помощи ITP. Также ITP может быть
использован для анализа масштабируемости приложения. Например, если заранее
известны характеристики компьютерной системы (число процессоров или ядер), на
которой будет функционировать приложение, то ITP можно использовать для подбора
оптимального числа потоков.
Итак, ITP может оказать разработчикам
существенную помощь при решении проблем, связанных с производительностью
многопоточного приложения. Перечислим основные варианты использования
Intel®
Thread
Profiler:
-
анализ эффективности распределения вычислительной
нагрузки между потоками (подраздел 4.1, лабораторная работа №1);
-
анализ эффективности обращения к разделяемым ресурсам
(подраздел 4.2, лабораторная работа №2);
-
определение наиболее медленных потоков и, как
результат, нуждающихся в оптимизации (лабораторная работа №1);
-
выбор оптимальной архитектуры многопоточного
приложения (число потоков, алгоритм, примитивы синхронизации) (лабораторная
работа №2);
-
анализ эффективности работы с потоками и примитивами
синхронизации (лабораторная работа №2);
-
анализ масштабируемости приложения на вычислительных
узлах с различным числом процессоров.
Таким образом,
ITP является весьма удобным и эффективным инструментом для поиска причин низкой
производительности многопоточного приложения и последующей помощи в их
устранении.
Технические характеристики
Intel® Thread Profiler
Поддерживаемые методы создания многопоточных
приложений
ITP позволяет
профилировать многопоточные приложения, созданные на основе технологий OpenMP, Windows threads, POSIX threads.
Инструмент имеет два
режима: «OpenMP» и
«Threaded». Первый из
них используется для анализа приложений, созданных с использованием OpenMP и
скомпилированных компиляторами Intel®. Этот режим предлагает
возможности сбора и отображения следующей информации:
-
затраты на синхронизацию, накладные расходы на
поддержку работы с потоками;
-
дисбаланс вычислительной нагрузки;
-
сравнение результатов разных запусков.
Главной особенностью этого режима является возможность оценивания
потенциальной масштабируемости, что очень удобно при создании параллельного
прототипа приложения.
Второй режим является более общим – он обеспечивает анализ OpenMP приложений и
многопоточных приложений, основанных на использовании Windows threads или POSIX
threads. В этом режиме отображается следующая информация:
-
аналогичные «OpenMP» режиму данные по потокам
программы и уровню паралеллизма;
-
критический путь программы;
-
распределение временных затрат по критическому пути
на:
-
исполнение;
-
синхронизацию;
-
ожидание;
-
блокировку.
-
связь потоковых
событий с исходным кодом.
Режим «Threaded» предоставляет более богатые
возможности, поэтому мы сосредоточимся на рассмотрении именно этого режима.
Системные требования
Аппаратное обеспечение
Минимальные
требования:
-
Процессор Intel® Pentium 4;
-
ОЗУ 512 МБ;
-
Свободное дисковое пространство 300 МБ.
Рекомендуемые требования:
-
Процессор Intel® Pentium 4, поддерживающий технологию
Hyper-Threading, или процессор Intel® Xeon;
-
ОЗУ 2 ГБ.
Программное обеспечение
Минимальные требования:
-
Microsoft® Windows® XP Professional, или Microsoft®
Windows® Server 2003.
-
Microsoft® Visual C++® 6.0 или выше.
-
Microsoft® Internet Explorer® 6.0 или выше.
-
Adobe® Acrobat® Reader.
Для анализа OpenMP-приложений и инструментации на
уровне исходных кодов требуется следующее программное
обеспечение:
-
Intel® C++ Compiler 8.1 или выше для Windows® для
архитектуры IA-32;
-
Intel® C++ Compiler 9.1 или выше для Windows® для
архитектуры Intel® EM64T;
-
Intel® Fortran Compiler для Windows® 8.1, Package ID:
w_fc_pc_8.1.023 или выше.
Основные концепции и понятия профилирования
Понятие критического пути
Первое понятие, которое нам
понадобится – критический путь (critical path).
Это понятие является ключом к пониманию всего процесса профилирования, поэтому
очень важно хорошо усвоить его. Прежде чем дать формальное определение этого
понятия, попытаемся понять его суть на примере.
Представим себе следующее
многопоточное приложение: имеется основной поток, который подготавливает данные
и производит их первичную обработку, а также один дочерний поток, который
завершает обработку и выводит результаты. Простейшая иллюстрация этого примера –
физическое моделирование, в котором основной поток занят вычислениями (например,
решением разностной схемы), а дочерний – подготовкой к визуализации и
непосредственно визуализацией результатов вычислений. Часто подобные
взаимодействия реализуются в виде конвейера, поскольку в то время как один из
потоков работает с устройствами ввода-вывода, второй поток может нагружать
процессор вычислениями.
В нашем случае, как только
первый поток вычислил первую порцию данных для отображения, он может начинать
вычисление следующей порции, а второй поток параллельно с этим начнет
визуализацию. Важно при этом обеспечить синхронизацию между потоками, чтобы не
допустить уничтожения данных до того как они были
визуализированы.
Ниже графически представлено
взаимодействие потоков в случае, если бы требовалось выполнить только две
итерации. Потокам в нашем приложении соответствуют горизонтальные линии,
сплошные участки соответствуют активному состоянию потоков, а пунктирные –
состоянию ожидания. Диагональные линии соответствуют сигналам, передаваемым
между потоками, а проекции этих линий на ось времени соответствует временам
прохождения сигналов. Кружками обозначены все события, в результате которых
изменяются состояния потоков (создание/завершение, блокировка/активизация).
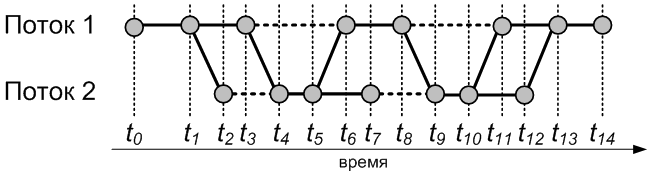
Рис. 2. Пример
критического пути многопоточного приложения
Рассмотрим диаграмму подробнее. В начальный
момент времени существовал только один поток, выполняющийся последовательно.
Затем в момент времени t1
происходит создание дочернего потока, который начинает функционировать в момент
времени t2, но сразу
попадает в состояние ожидания, поскольку данные для визуализации еще не
подготовлены. Затем в точке t3 завершаются вычисления, и
дочерний поток начинает визуализацию подготовленных данных, которая продолжается
с момента t4 до момента t7. Заметим, что второй поток
может освободить массивы с результатами вычислений сразу после того, как
переведет их в формат, необходимый для графического представления (момент
времени t5). За счет
этого и достигается распараллеливание в рассматриваемом приложении. Можно
видеть, что потоки работают параллельно на промежутке времени между моментами t6 и t7. Далее осуществляется еще
одна итерация, после чего в момент времени t12 второй поток завершает
свое исполнение, а в момент времени t14 завершается весь
процесс.
Рассмотренная диаграмма
представляет собой граф. Вершинам, как уже говорилось, соответствуют события,
изменяющие состояние потоков, а ребрам – действия, выполняемые потоками (мы не
учитываем пунктирные линии). При этом ребрам можно сопоставить вес, равный
времени, затрачиваемому на выполнение действия. Путем
приложения называется любой путь в указанном графе, соединяющий
вершины, соответствующие началу и завершению приложения. Критическим путем приложения называется путь, имеющий
максимальную сумму весов входящих в него ребер. Приложения со многими потоками
могут иметь большое число путей, однако в нашем случае приложение имеет всего
два пути, каждый из которых можно назвать критическим, так как суммы их весов
совпадают.
Важность понятия критического
пути определяется тем, что сумма весов
ребер в критическом пути равна времени выполнения приложения. Из этого факта
следует следующий принцип: необходимо оптимизировать прежде всего те участки
приложений, которые вошли в критический путь, поскольку именно они определяют
производительность.
Таким образом, профилирование и оптимизация
приложения неразрывно связаны с процессом анализа критического пути. Критический
путь – это первое, на что нужно обращать внимание, поскольку не входящие в него
участки приложения вносят меньший вклад в суммарное время работы приложения.
Далее мы увидим, что ITP позволяет
строить критический путь приложения и предоставляет различные средства для его
анализа.
Состояния потоков
При анализе критического пути
пользуются таким понятием как состояние потока (thread
state). А именно, поток может находиться в трех
состояниях:
-
Активное состояние (active) – поток исполняется в настоящее время;
-
Состояние активного ожидания (spin) – постоянный опросом в цикле состояния блокировки (например, при использовании pthread_spin_lock());
-
Состояние ожидания (wait) –ожидание завершения какой-либо блокирующей операции
(например, операции ввода-вывода).
Понятие категорий времени
Рассмотрим такую
характеристику, как эффективность использования аппаратных ресурсов активными
потоками приложения. Для этого введем два параметра: уровень
параллелизма (concurrency) и поведение
(behavior).
Уровни параллелизма
используются для обозначения того, насколько полно потоки нагружают процессоры
вычислительного узла. Так, одновременная работа двух потоков на двухъядерном
процессоре означает эффективное использование его ресурсов (full utilization), на одноядерном – сверхиспользование
(over utilization), а на четырехъядерном –
недостаточно эффективное использование (under
utilization).
Существует несколько типов
поведения потока в активном состоянии:
-
Сдерживание
(impact) – ситуация, когда поток сдерживает
выполнение другого потока (например, поток занял мьютекс, освобождения
которого ожидают другие потоки);
-
Блокировка
(blocking) – приостановка потока в результате вызова
блокирующих функций (например, операций ввода/вывода);
-
Критический путь
(critical
path) –
ситуация, когда поток выполняет участок кода, входящий в критический путь, при
отсутствии других ожидающих потоков.
Уровень параллелизма и
поведение независимы друг от друга, и в совокупности они называются категориями времени (time
categories) и
характеризуют эффективность работы активных потоков. Собственно
весь анализ производительности состоит в том, чтобы оценить каждый участок
критического пути по этим двум параметрам и определить наиболее проблемные
участки приложения.
В
ITP используется
несколько видов представления критического пути, каждое из которых мы
впоследствии подробно изучим. Для удобства анализа каждый участок критического
пути окрашивается в определенный цвет в зависимости от уровня параллелизма и
поведения потока на этом участке. На рис. 3 представлена сводная таблица
используемых цветов. n обозначает
число активных потоков приложения, а p
– число процессоров (ядер).
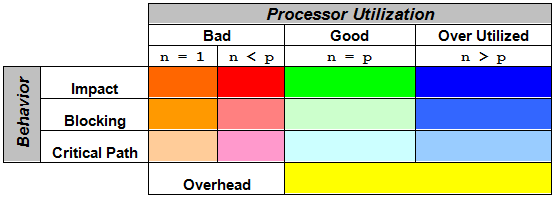
Рис. 3. Цвета,
используемые для обозначения категорий времени
Рассмотрим приведенную таблицу
подробнее, чтобы знать впоследствии, на какие цвета нужно обращать внимание
прежде всего. Сначала исследуем связь числа потоков и числа ядер. Как видно из
таблицы, для обозначения этого соотношения используется четыре цвета: оранжевый,
красный, зеленый и синий. Зеленый цвет – признак оптимального соотношения, когда
число ядер и потоков совпадает. Синий цвет используется для обозначения
ситуаций, когда одновременно работает больше потоков, чем доступно ядер. Как
результат, потоки могут мешать работе друг друга. Присутствие красного и
оранжевого цветов в окраске критического пути чаще всего свидетельствует о
необходимости перестройки приложения. Эти цвета означают, что используются не
все ядра процессора и можно получить дополнительное ускорение за счет более
эффективного распараллеливания.
Рассмотрим теперь второй параметр – тип
поведения потоков. Для обозначения типа поведения потока цветом используется
изменение яркости. При этом используется простое правило: чем ярче цвет участка,
тем большего внимания от разработчика он требует. Самый яркий цвет используется
для указания impact-состояния потока,
поскольку прежде всего необходимо сокращать время ожидания потоков друг другом.
Далее по важности следует blocking-состояние, которое тоже
требует пристального контроля, так как нужно минимизировать время ожидания
потоков. Последним идет состояние critical
path.
Имеется особая категория
времени, обозначаемая желтым цветом и указывающая на непроизводительные издержки (overhead) в многопоточном приложении. Под
непроизводительными издержками понимаются накладные расходы на создание потоков,
управление и синхронизацию между потоками. Другими словами, эта величина
показывает количество процессорного времени, израсходованного на поддержку
работы потоков. Чаще всего большая доля желтого цвета в критическом пути
свидетельствует о чрезмерно частом вызове функций синхронизации и необходимости
перепроектирования приложения.
Теперь, зная о категориях
времени, мы можем сказать, какие цвета будут содержаться на критическом пути
нашего примера из подраздела 3.1.
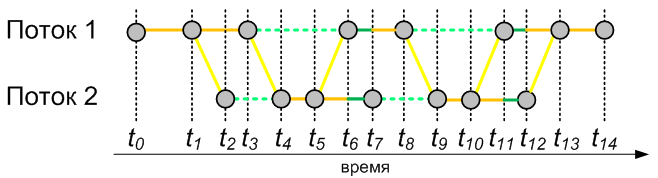
Рис. 4. Пример
раскраски критического пути многопоточного приложения в соответствии с
категориями времени
Итак, подведем итоги:
профилирование многопоточного приложения основано на построении критического
пути и его анализе с точки зрения эффективности использования процессора. Для
этого выделяют категории времени, часть из которых считается проблемными и
свидетельствует о неправильной организации многопоточного приложения.
Деятельность разработчика, таким образом, состоит в нахождении проблемных
участков критического пути, выявлении причин их появления (соотнесение с
исходным кодом) и в последующем их разрешении.
Проблемы производительности, определяемые при помощи профилирования
Мы уже говорили ранее, что профилирование
многопоточных приложений имеет свою специфику. ITP ориентирован
на выявление проблемных ситуаций, характерных именно для многопоточных
приложений, таких как: неэффективное управлением потоками, ошибки при выборе и
использовании примитивов синхронизации, неправильное распределение
вычислительной нагрузки и другие недостатки.
Рассмотрим далее наиболее распространенные
ошибки и то, как ITP может помочь
разработчикам в их обнаружении и исправлении.
Распределение вычислительной нагрузки
Весьма распространенной ошибкой
является неравномерное распределение нагрузки между потоками. Общее время работы
приложения в значительной степени зависит от времени работы самого медленного из
его потоков. Очевидно, приложение будет работать быстрее всего, если нагрузка
поделена между потоками поровну – тогда они завершают работу одновременно и за
минимальное время.
Типичный пример: стоит задача
обработки множества заявок, трудоемкость каждой из которых заранее неизвестна. В
такой ситуации не всегда правильно разделять множество заявок поровну между
потоками. Дело в том, что один поток может, например, получить все сложные
заявки, в результате чего он станет узким местом в приложении.
Проблема распределения вычислительной
нагрузки в ряде ситуаций решается достаточно просто. Первый признак ее появления
– большая доля последовательных вычислений в приложении, что легко
обнаруживается при анализе критического пути. Кроме того, ITP позволяет
определить время работы каждого из потоков. При этом, если наблюдается
существенное различие между временами работы нескольких потоков (при том, что
они выполняют одинаковые действия), это свидетельствует о неравномерном
распределении нагрузки.
Для рассмотренного выше примера
в качестве решения можно предложить не делать априорного разделения множества
заявок между потоками. Вместо этого стоит разрешить потокам выбирать из общей
очереди новую заявку каждый раз после того, как была обработана предыдущая.
Тогда пока один поток обрабатывает одну сложную заявку, второй поток успеет
обработать несколько простых, и в результате можно ожидать более
сбалансированного времени работы потоков.
Синхронизация и производительность
Аспекты производительности, связанные с
синхронизацией между потоками, требуют особого внимания. Неправильно выбранная
стратегия может привести к тому, что параллельная версия приложения будет
выполняться даже медленнее, чем последовательная. Поэтому разработчик должен
тщательно продумать используемую в его приложении модель синхронизации, и
ITP способен оказать ему в этом
существенную помощь.
Рассмотрим основные вопросы,
связанные с синхронизацией.
Выбор примитивов
синхронизации
Существует достаточно большое
число примитивов синхронизации: мьютексы, семафоры, мониторы, критические
секции. Все они имеют одинаковое назначение (обрамление критических областей
программы), но эффективность (дополнительные накладные расходы) их работы может
существенно различаться. При этом разработчику важно выбрать наиболее подходящий
тип примитива синхронизации для каждой конкретной ситуации.
Рассмотрим, например, ситуацию, когда в
приложении имеется некоторый целочисленный счетчик, являющийся глобальной
переменной. При этом, если мы в приложении используем каждый раз увеличение
этого счетчика на единицу, то выбор такого объекта как мьютекс является
нерациональным. Гораздо эффективнее использовать атомарную функцию ОС
Windows
InterlockedIncrement. Кроме того, при разработке модели синхронизации следует делать выбор в
пользу примитивов пользовательского уровня (CriticalSection,
например), поскольку они работают быстрее, так как не генерируют системных
вызовов операционной системы.
ITP способен
помочь в выборе наиболее подходящего примитива, позволяя определить время,
затраченное на работу с каждым из объектов синхронизации. Таким образом,
разработчик может реализовать несколько моделей синхронизации и сравнить их
производительность между собой.
Синхронизация между потоками
Разработчикам следует
придерживаться следующей рекомендации: производить синхронизацию между потоками
как можно реже. То есть необходимо сделать потоки максимально независимыми,
чтобы избежать ситуаций, когда они ожидают друг друга. Слишком частое обращение
нескольких потоков к разделяемому ресурсу приводит к тому, что большое
количество времени потоки простаивают, находясь в состоянии
ожидания.
Часто встречающаяся ситуация –
это совместное использование одного и того же объекта несколькими потоками.
Чтобы избежать блокировки потоков при обращении к объекту, часто используется
подход, при котором каждый из потоков получает копию объекта в свое личное
пользование. Так, в частности, поступают при работе нескольких пользователей с
одной таблицей базы данных.
В данной ситуации ITP
используется следующим образом. С его помощью определяются объекты, обращение к
которым происходит наиболее часто. Затем анализируется насколько затратно столь
частое обращение к объекту. Если обнаруживается, что производительность
существенно страдает, разработчику следует попытаться изменить архитектуру
приложения. Хороший пример – замена глобальных переменных
локальными.
Непроизводительные издержки при
работе с потоками
Важный момент при работе с
потоками – появление дополнительных накладных расходов. Конечно, эти затраты
гораздо меньше чем при управлении процессами, но все равно они могут оказаться
весьма существенными. Основная рекомендация здесь состоит в следующем: потоки за
время своей жизни должны совершать работу гораздо большей сложности, чем
трудоемкость их собственного создания, уничтожения и управления
ими.
Понятно, что если накладные
расходы на управление потоками будут преобладать над их полезной деятельностью,
то производительность приложения только пострадает.
ITP позволяет
определить долю непроизводительных издержек от общего времени работы приложения.
Если она оказывается слишком велика, скорее всего, приложение требует
перепроектирования. Так, например, если создается система, обслуживающая
поступающие в режиме реального времени запросы, то для обработки лучше содержать
пул потоков, вместо того, чтобы создавать новый поток для каждого очередного
запроса.
Общий порядок работы с
инструментом
Порядок работы с Intel® Thread Profiler включает в себя
следующие шаги:
-
инструментация приложения;
-
профилирование приложения;
-
анализ полученной информации.
На первом шаге
происходит подготовка приложения к профилированию – так называемая
инструментация. Затем осуществляется запуск, и в процессе выполнения происходит
накопление статистической информации о работе приложения. Собранная информация
представляет собой трассу приложения, которая затем обрабатывается ITP и
представляется в графическим виде, удобном для понимания. После этого
разработчик может начинать непосредственно анализ производительности
приложения.
Далее мы приведем
рассмотрение процессов инструментации и профилирования. О том, как эти процессы
осуществляются в ITP,
мы расскажем в разделе 6.3.
Инструментация приложения
Инструментация представляет собой встраивание в
приложение дополнительных вызовов, при помощи которых профилировщик получает
информацию о работе приложения. Эти вызовы могут быть добавлены как на уровне
исходного кода приложения, так и в уже скомпилированное приложение. В связи с
этим различают инструментацию исходных
кодов (source instrumentation) и бинарную инструментацию (binary instrumentation). ITP поддерживает оба этих
способа.
Бинарная инструментация
выполняется автоматически при запуске приложения из ITP. То есть вы имеете
возможность взять любое уже скомпилированное приложение и немедленно начать
профилировку. Однако полезность информации, которую вы получите, существенно
зависит от опций, с которыми было скомпилировано приложение. Так, если в него
была включена отладочная информация, то вы сможете обращаться к исходному коду
из ITP. В противном случае вам будет доступен лишь ассемблерный код, что может
быть весьма неудобно.
В связи с этим, обычная
процедура состоит в следующем: разработчик компилирует свое приложение со всеми
необходимыми опциями, а затем использует бинарную инструментацию. Мы рассмотрим
этот процесс подробнее в разделе 6.2.
Второй тип
инструментации используется крайне редко. Создатели ITP рекомендуют
инструментацию исходных кодов лишь в двух ситуациях:
-
Бинарная инструментация недоступна. Это справедливо
для систем, созданных для работы на архитектурах Intel® Itanium и Intel®
EM64T.
-
Необходимо запустить инструментированное приложение
вне Intel® Thread Profiler.
Далее под
инструментацией мы будем понимать именно бинарную инструментацию, поскольку
именно с ней нам придется работать.
Профилирование
приложения
После того как
приложение было инструментировано, можно начинать профилирование. ITP осуществляет запуск
приложения, в процессе которого собирает его трассу. В нее включается следующая
статистическая информация:
-
идентификаторы созданных потоков;
-
время создания и уничтожения каждого потока;
-
количество времени, которое каждый поток провел в
состоянии ожидания;
-
эффективность использования приложением ядер
процессора на каждом участке критического пути.
ITP также
регистрирует большое число других событий и вызовов API, информация о которых
может быть полезна при оптимизации производительности многопоточного
приложения.
При профилировании
старайтесь следовать следующим советам:
-
Избегайте запускать другие приложения во время
профилирования. Деятельность посторонних приложений (особенно потребляющих
много ресурсов) может существенно исказить интересующую вас информацию.
-
Производите профилирование несколько раз и для
анализа выбирайте тот запуск, когда приложение отработало быстрее всего. Этот
запуск соответствует ситуации, когда на ваше приложение было меньше всего
воздействий, поэтому эта информация ближе всего к «идеальному» профилю вашего
приложения.
Литература
-
«Developing Multithreaded Applications: A Platform
Consistent Approach», Intel Corporation, March 2003.
-
«Threading Methodology: Principles and Practices», Intel
Corporation, March 2003.
-
«Multi-Core Programming for Academia», Student Workbook,
by Intel.
-
«Multi-Core Programming», book by Sh. Akhter and J.
Roberts, Intel Press 2006.
-
«Intel® Thread Profiler. Getting Started
Guide».
-
«Intel® Thread Profiler. Guide to Sample
Code».
-
«Intel® Thread Profiler
Help».




