В последние
годы направление развития компьютерной техники изменилось: разработчики
аппаратного обеспечения все больше и больше наращивают мощность вычислительных
ресурсов не за счет увеличения тактовой частоты процессоров, а за счет
использования в вычислителях нескольких обрабатывающих блоков и, следовательно,
предоставляют возможность параллельных вычислений. Многопроцессорные и
многоядерные сервера, суперкомпьютеры с массивным параллелизмом, а также
кластера находят применение во всех
областях науки и техники.
Главной задачей разработчика программного обеспечения становится наиболее
эффективное использование предоставляемой мощности. Развитие любой отрасли, будь
то промышленность или создание программного продукта, приводит к тому, что
выделяются удачные решения определенных проблем и те решения, которые привели к
нерациональному использованию ресурсов. В результате процесса отбора успешных
подходов появляются шаблонные подходы (шаблоны), которые, будучи примененными
при решении задачи определенного типа, ведут к наиболее удачному ее решению.
Этот процесс не обошел стороной и область параллельного программирования.
Выбор структуры параллельной программы
На текущий
момент существует огромное количество структур организации параллельных
программ. Зачастую структура программы выбирается из интуитивных соображений и в
процессе работы над алгоритмом часто меняется. Между тем, для сокращения времени
разработки алгоритма существует ряд отработанных схем, которые показывают
хорошие результаты в работе и облегчают отладку. Наиболее часто встречающихся
схем шесть:
-
Схема “разделяй и властвуй”
-
Конвейерная схема обработки данных
-
Рекурсивная схема обработки данных
-
Схема, основанная на геометрическом разделении данных
-
Параллелизм задач
-
Параллелизм, основанный на возникновении
событий
Для выбора
схемы алгоритма удобно использовать следующее дерево решений:
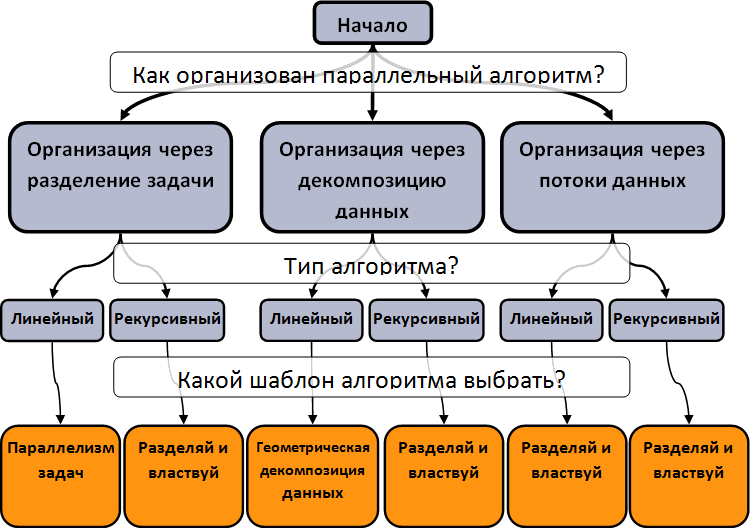
Прежде
всего, стоит проанализировать алгоритм на предмет возможностей, которые он
представляет для распараллеливания. В результате анализа для алгоритма можно
выбрать наиболее предпочтительный тип распараллеливания. Наиболее популярных
типа три:
-
Организация алгоритма через разделение решаемой
задачи на подзадачи
-
Разделение обрабатываемых данных между
вычислительными элементами (т.е. процессорами или ядрами процессоров)
-
Разделение задачи обработки потока данных на стадии
Каждый тип алгоритма определяется набором характерных черт. Для
определения типа алгоритма следует выделить его ключевые особенности:
-
Данных мало, алгоритм обработки данных достаточно
трудоемкий → Организация через разделение задачи на подзадачи
-
Дынных
много, при разделении данных на блоки
большая часть вычислений над выделенными частями данных может быть выполнена
без обращения к внешним частям данных → Организация через декомпозицию данных
-
Процесс обработки потока данных трудоемкий, но
может быть разделен на независимые стадии → Организация через
потоки данных
После
выбора типа алгоритма в зависимости от того, является ли он рекурсивным или
линейным, происходит выбор соответствующего шаблона организации параллельного
вычислений для решения поставленной задачи.
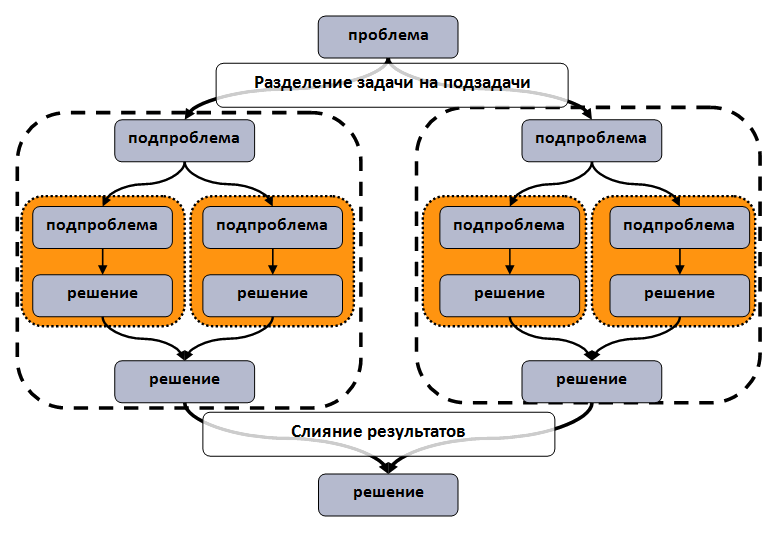
Схема «разделяй и властвуй»
Рассмотрим
алгоритм, устроенный таким образом, что для обработки данных необходимо
рекурсивно вызывать одну и туже функцию (или ограниченное множество функций).
Также предполагается, что функции, вызываемые на одном уровне рекурсии, не имеют
конфликтов по чтению и записи используемых данных. В этом случае задачу можно
сформулировать в терминах “разделяй и властвуй”: общая задача разделяется на
независимые подзадачи. Подзадачи, в свою очередь, также могут быть разделены на
более мелкие задачи. Распараллеливание становится элементарным: на
вычислительные элементы назначаются обработка отдельных ветвей решения задачи.
Для достижения наибольшей эффективности и балансировки вычислений степень
раздробления общей задачи на подзадачи может быть различной.
Структурная
схема шаблона представлена на рисунке:
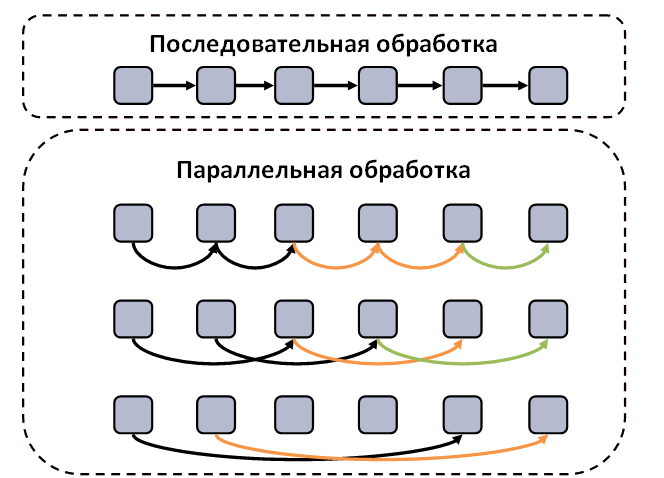
Конвейерная схема обработки данных
Шаблон
предполагает, что при решении задачи обрабатывается непрерывный поток блоков
данных. Каждый блок обрабатывается вычислительно сложной функцией. В этом случае
возможно распараллеливание задачи. В этом случае для распараллеливания
вычислительную функцию разделяют на независимые части или стадии, которые могут
выполняться на независимых вычислительных элементах. Каждая стадия принимает
данные от предыдущей стадии или из входного потока данных. После приема данных
выполняется часть работы алгоритма. Затем результаты вычислений отправляются на
обработку следующей стадии (следующему вычислительному элементу).
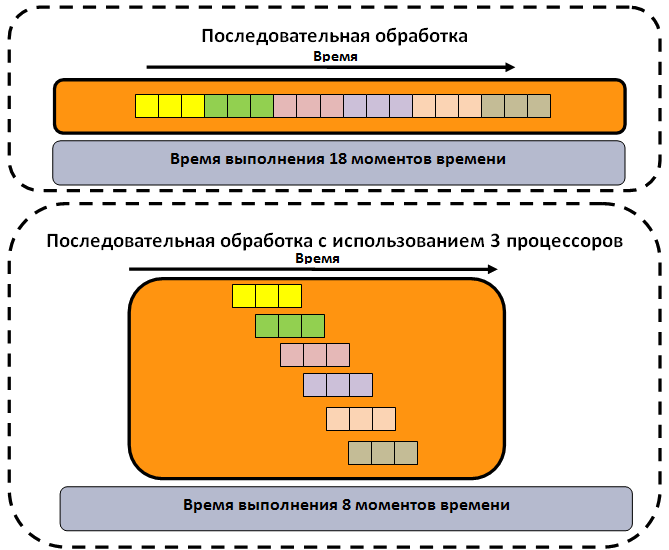
На
рисунке представлен пример, который иллюстрирует процесс достижения ускорения
решения задачи за счет использования конвейерной схемы:
Рекурсивная обработка данных
Часто
программные комплексы работают со сложными структурами данных, такими как
списки, деревья, графы и т.п. При обработке таких структур бывает необходимо
выполнить ряд действий над всей структурой данных. Действием может являться
поиск элемента, подсчет контрольной суммы или более сложные функции. Шаблон
представляет общую схему параллельной обработки таких данных.
Для
обработки данных, структура данных разделяется на части, каждая из частей
ассоциируется с вычислительным элементом. На первом шаге каждый вычислительный
элемент выполняет действия над локальной частью данных. Далее производится
“свертка” структуры данных: вместо старой структуры формируется новая, которая
состоит из обработанных элементов меньшего размера. Для новой структуры данных
итерация повторяется.
На рисунке
представлена структурная схема параллельного решения классической задачи
суммирования всех элементов списка на каждом узле списка(Стрелки обозначают
вычисления. Стрелки разного цвет обозначают вычисления, которые выполняются на
разных вычислительных элементах):
Геометрическое разделение данных
Довольно
часто встречаются задачи, в которых один и тот же алгоритм обрабатывает большое
число данных. В этом случае для разработки параллельных алгоритмов хорошо
применим шаблон разделения данных, который предполагает разделение данных между
вычислительными элементами и выполнение одного и того же алгоритма обработки над
блоками данных. При этом выделяют два случая:
-
Для выполнения вычислений одним процессом/потоком не
требуется внешних данных
-
Вычисления требуют внешних данных
В первом
случае вычисления производятся аналогично последовательному варианту, а во
втором необходимы дополнительные механизмы передачи данных и
синхронизации.
Пример
разделения данных приведен ниже (здесь и далее жирной линией обозначен блок
данных, который обрабатывается в данный момент времени, а фиолетовым цветом
обозначены данные, которые необходимы для вычислений):

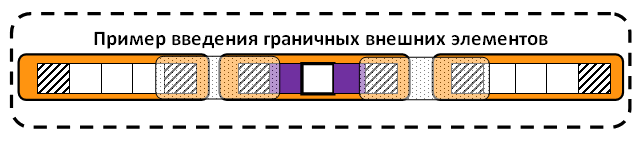
Для
уменьшения накладных расходов и упрощения логики программы рекомендуется на
вычислительных элементах заводить локальные копи необходимых внешних данных,
которые обновляются по мере необходимости. Структурная схема представлена ниже
(заштрихованными клетками обозначены локальные копии внешних данных):
Параллелизм, основанный на возникновении
событий
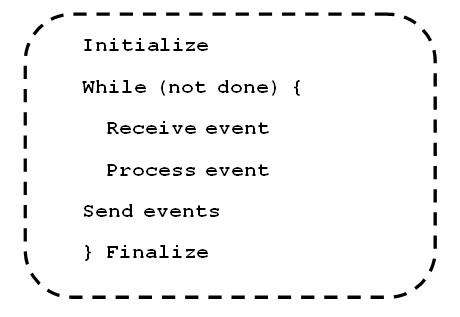
Шаблон параллелизма, основанного на
возникновении событий, напоминает шаблон организации параллельных вычислений с
использованием конвейеров. Общая задача делится на стадии, и они выполняются
параллельно. Отличие заключается в том, что стадии не фиксированы, в зависимости
от внешних условий или хода алгоритма могут появляться новые стадии или часть
стадий может пропадать. Общая схема алгоритма представлена ниже:
Данная
схема организации сложнее конвейерной, но вместе с тем является более гибкой и
сбалансированной.
Параллелизм задач
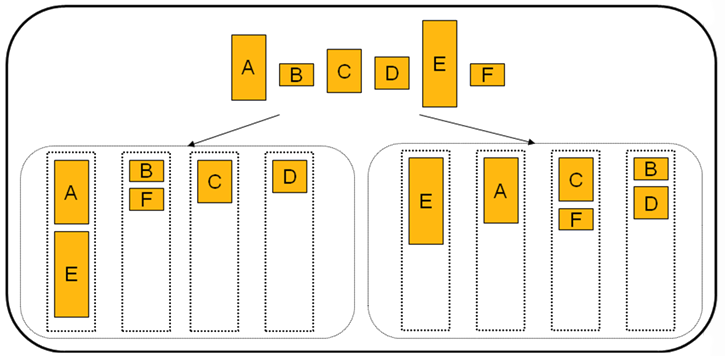
Шаблон предполагает, что программа
является линейной, но некоторые части задачи могут исполняться независимо. В
этом случае все независимые задачи помешаются в очередь и последовательно
назначаются вычислительным элементам. Основная задача, которая стоит в этом
случае перед программистом, - это оптимально распределить задачи по
вычислительным элементам. Ниже приведен пример плохого и правильного
распределения задач:
Для
распределения задач существуют как статические, так и динамические алгоритмы
планирования. Статические определяют порядок выполнения подзадач на этапе
запуска программы на основе эвристик и предположений о подзадачах. Динамические,
в отличие от статических, определяют порядок выполнения подзадач на этапе
исполнения программы, основываясь на предыстории исполнения программы, и в
автоматическом режиме выполняют балансировку нагрузки.
Литература
- Timothy G. Mattson, Beverly A. Sanders, Berna L. Massingill. “Patterns for Parallel Programming” copyright (c) 2005 byPearson Education, Inc. ISBN 0-321-22811-1
- Гергель В.П. Теория и практика параллельных вычислений. – М.: Интуит; Бином, 2007.
- Kumar V., Grama A., Gupta A., Karypis G. «Introduction to Parallel Computing». – The Benjamin/Cummings Publishing Company, Inc., 1994.
- Rajkumar Buyya. «High Performance Cluster Computing. Volume 1: Architectures and Systems. Volume 2: Programming and Applications.» Prentice Hall PTR, Prentice-Hall Inc., 1999.
- Воеводин В.В., Воеводин Вл.В.. «Параллельные вычисления». СПб., БХВ – Петербург, 2002.
- Немнюгин С., Стесик О. (2002). Параллельное программирование для многопроцессорных вычислительных систем – СПб.: БХВ-Петербург.
- Grama, A., Gupta, A., Kumar V. (2003, 2nd edn.). Introduction to Parallel Computing. – Harlow,
England: Addison-Wesley.




