Для
дальнейшей систематики мультипроцессоров учитывается
способ построения общей памяти. Возможный подход – использование единой
(централизованной) общей памяти
(shared
memory
). Такой подход обеспечивает однородный доступ к памяти
(uniform
memory
access
or
UMA)
и служит основой для построения векторных параллельных процессоров
(parallel
vector
processor
or
PVP)
и симметричных мультипроцессоров (symmetric
multiprocessor
or
SMP). Среди примеров первой группы суперкомпьютер Cray
T90, ко второй группе относятся IBM eServer, Sun StarFire, HP Superdome, SGI
Origin и др.
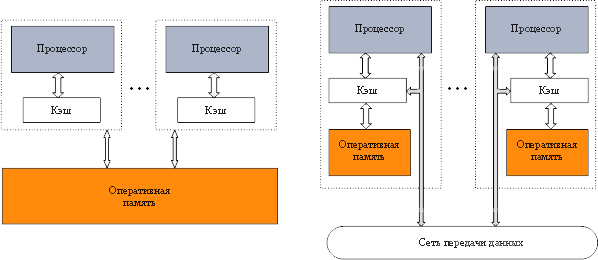
Архитектура многопроцессорных систем с общей (разделяемой)
памятью: системы с (а) однородным и (б) неоднородным доступом к памяти
Одной из
основных проблем, которые возникают при организации параллельных вычислений на
такого типа системах, является доступ с разных процессоров к общим данным и
обеспечение, в этой связи, однозначности
(когерентности) содержимого разных кэшей (cache coherence problem). Дело в том, что при
наличии общих данных копии значений одних и тех же переменных могут оказаться в
кэшах разных процессоров. Если в такой ситуации (при наличии копий общих данных)
один из процессоров выполнит изменение значения разделяемой переменной, то
значения копий в кэшах других процессорах окажутся не соответствующими
действительности и их использование приведет к некорректности вычислений.
Обеспечение однозначности кэшей обычно реализуется на аппаратном уровне – для
этого после изменения значения общей переменной все копии этой переменной в
кэшах отмечаются как недействительные и последующий доступ к переменной
потребует обязательного обращения к основной памяти. Следует отметить, что
необходимость обеспечения когерентности приводит к некоторому снижению скорости
вычислений и затрудняет создание систем с достаточно большим количеством
процессоров.
Наличие
общих данных при выполнении параллельных вычислений приводит к необходимости синхронизации взаимодействия
одновременно выполняемых потоков
команд. Так, например, если изменение общих данных требует для своего выполнения
некоторой последовательности действий, то необходимо обеспечить взаимоисключение (mutual exclusion) с тем, чтобы эти
изменения в любой момент времени мог выполнять только один командный поток.
Задачи взаимоисключения и синхронизации относятся к числу классических проблем,
и их рассмотрение при разработке параллельных программ является одним из
основных вопросов параллельного программирования.
Общий доступ к данным может быть обеспечен и при
физически распределенной памяти (при этом, естественно, длительность доступа уже не
будет одинаковой для всех элементов памяти). Такой подход именуется как неоднородный
доступ к памяти (non-uniform
memory
access
or NUMA). Среди систем с таким типом
памяти выделяют:
-
Системы, в которых для представления данных
используется только локальная кэш-память имеющихся процессоров (cache-only
memory
architecture
or COMA); примерами таких
систем являются, например, KSR-1 и DDM;
-
Системы, в которых обеспечивается когерентность локальных кэшей разных
процессоров (cache-coherent
NUMA or CC-NUMA); среди систем данного типа SGI Origin 2000, Sun
HPC 10000, IBM/Sequent NUMA-Q 2000;
-
Системы, в которых обеспечивается общий доступ
к локальной памяти разных процессоров без поддержки на аппаратном уровне
когерентности кэша (non-cache
coherent
NUMA or NCC-NUMA); к данному типу
относится, например, система Cray T3E.
Использование
распределенной общей памяти (distributed
shared
memory
or
DSM)
упрощает проблемы создания мультипроцессоров (известны примеры систем с
несколькими тысячами процессоров), однако, возникающие при этом проблемы
эффективного использования распределенной памяти (время доступа к локальной и
удаленной памяти может различаться на несколько порядков) приводят к
существенному повышению сложности параллельного
программирования.




